Its convenient to have a lexical score normalized from 0-1. Sadly BM25 scores tend to be all over the place (0.5? 5.1? 12.51?). Fine for ranking. Annoying for other goals. That’s why I wrote a post about one way to compute probabilities from BM25.
In that post, I allude to one hack that forces BM25 to 0-1. Let’s walk through it.
A query term’s BM25 score is IDF * TF.
Lucene’s TF is already normalized
Lucene drops the (k1 + 1) in the numerator of BM25, giving you:
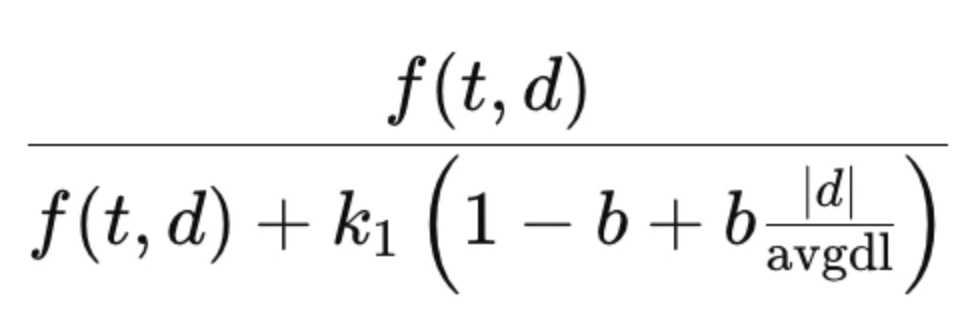
Now we’ve got a TF term bounded from 0-1. Nice.
Now we’ve got to tackle IDF. Here’s the standard IDF. Here N: num docs in corpus; n: doc frequency of this term.
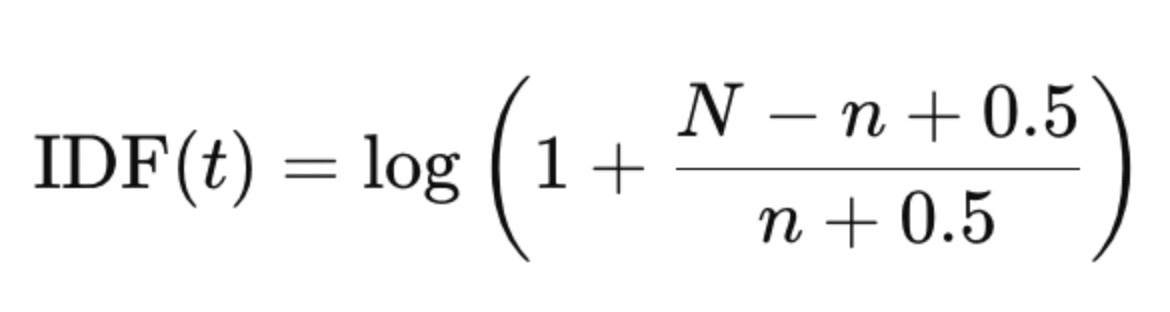
Turns out the max value of this function is log(N). So! just slap a log(N) denominator under that sucker. Now that too has become 0-1.
BM25 now ranges 0-1, while preserving in-query ranking.
It’s 100% a hack. What’s nice or problematic about this:
- 👎 You’re multiplying small numbers. Most IDFs/TF terms will be low, making the final result low
- 👍 You don’t need to know anything about distribution of BM25 scores (ie to do min/max or z-score normalization)
- 🤙 No calibration to try to be a proper probability. 0.5 BM25 here doesn’t equate to midpoint of your relevance labels, like in BB25.
- 🆗 Combining with other terms means dividing by number of query terms to stay between 0-1
Use with care.
-Doug
AI Powered Search training - late signup available - http://maven.com/search-school/ai-powered-search
This is part of Doug’s Daily Search tips - subscribe here
Upcoming events: Vectors Week

Join me for Vectors Week, a series of events about vector retrieval, hybrid search, and building your own vector database.

Doug Turnbull
More from DougTwitter | LinkedIn | Newsletter | Bsky